Stop using the _id field in Elasticsearch
These simple changes will dramatically improve Elasticsearch's performance.
Oftentimes, you only need to retrieve a few fields from Elasticsearch. If that’s the case, using doc_values for those fields can drastically improve your query performance.
But one field that is retrieved by default is the field _id. It might look like a harmless thing, but as we’ll see later on, it can hinder your system performance.
Another typical Elasticsearch use is as an auxiliary database, especially for full-text search where you’ll use Elasticsearch to retrieve the ids of the relevant documents.
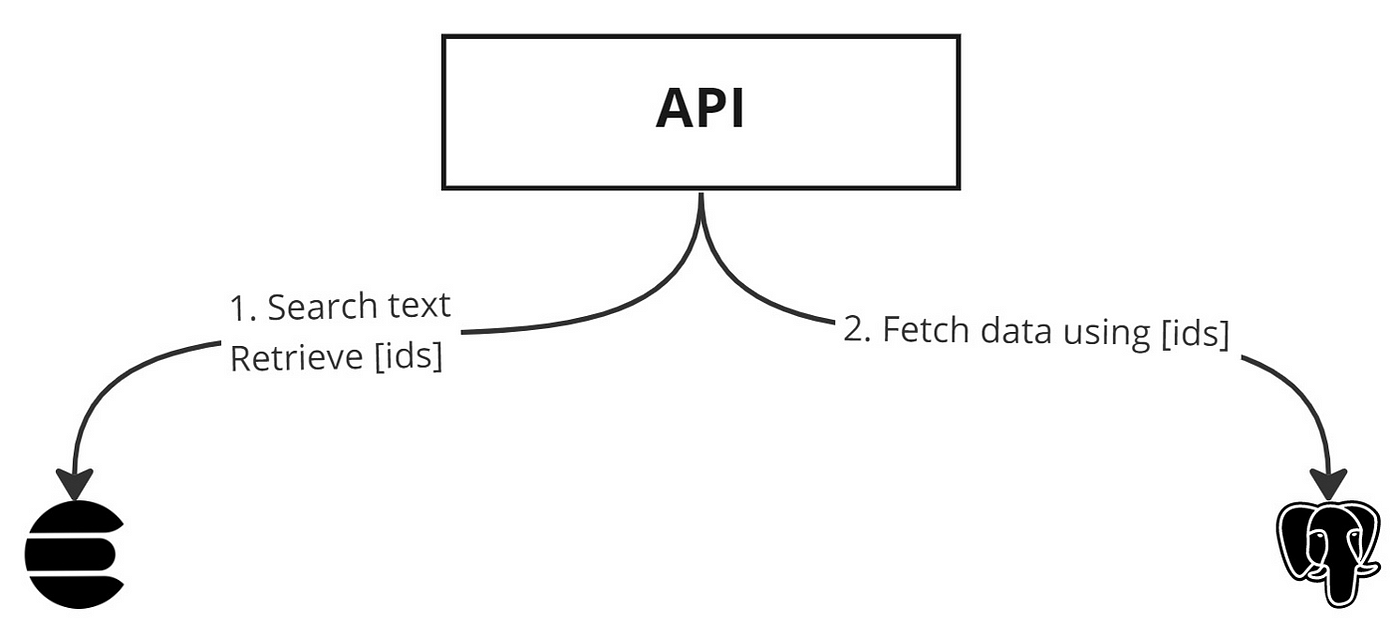
If you’re like a good part of the Elasticsearch user base, you’re probably saving your external id in the _id field to make things simple and avoid duplicating data. Or maybe you don’t even use _id but since it’s returned by default you end up using it indirectly.
The problem with this is that _id is saved using stored_fields which can have a bigger reading overhead when compared to doc_values.
Especially with Elasticsearch 7.10+ where stored_fields started being written/read in blocks of 80KB (previously it was 16KB). This was an optimization done by Lucene (the underlying search engine of Elasticsearch) in order to optimize document compression, especially for smaller documents.
More about this format later in this article.
How to increase Elasticsearch read performance
The solution is simple. You just need to start using doc_values and disable the retrieval of stored_fields (this includes the _id field!).
So a query like this:
GET test/_search
{
"query": {
"match_all": {}
},
"_source": false
}Becomes this:
GET test/_search
{
"query": {
"match_all": {}
},
"_source": false,
"stored_fields": "_none_",
"docvalue_fields": ["my_id_field"]
}"stored_fields": "_none_": This will disable the retrieval of all stored_fields like _source and _id."docvalue_fields": ["my_id_field"]: This allows you to retrieve only the selected doc_values fields.
Benchmark
Index Size: 1.3 million documents
Document Size: ~4KB
Queries: 10 000 queries with random match clauses

The results are as expected. Even for relatively small document sizes, we can see that excluding the _id from our results and retrieving only a doc_values field dramatically improves our latency. Expect to see even better results for bigger documents!
Deep dive into Lucene internals
We’ve concluded that it can be more efficient to discard _id and retrieve fields using doc_values and know how to make use of this knowledge in Elasticsearch.
For many of you reading this article, that’s probably enough. For the ones that want to understand better what’s happening behind the scenes to allow such behaviour, continue reading!
Stored Fields
For stored fields, each document is saved as a row that contains all the stored fields consecutively.
The first field is the “_id”, followed by other individual stored fields and “_source” is the last stored field in that row.
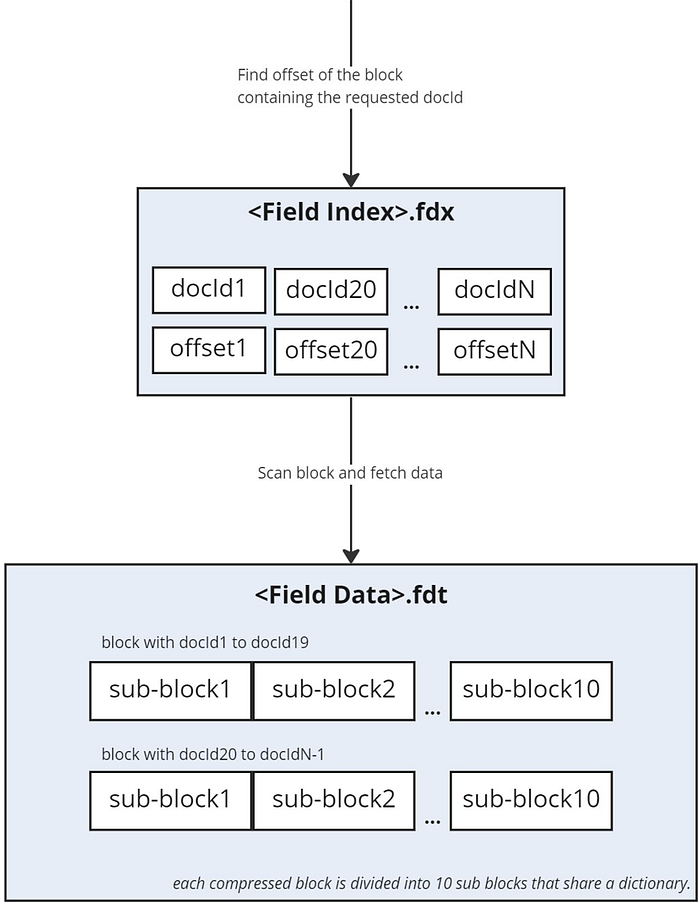
Previously, I oversimplified the way those blocks are saved in Lucene as you can see in the above diagram. In fact, they are split into 10*8 KB sub-blocks with a shared dictionary.
The benefits are twofold. You get better compression if you have small documents since you’ll have multiple documents inside each block.
For reading, since you can uncompress individual sub-blocks, you might get away with uncompressing only a sub-block to retrieve a specific field/document.
To retrieve a value, Lucene needs to read Field Index (.fdx) file first. This file stores two monotonic arrays (ascending order), one for the first Doc ID of each block of compressed documents, and another one for the corresponding offsets on disk. The array containing doc IDs is binary-searched in order to find the block that includes the expected doc ID, and the associated offset on disk is retrieved from the second array.
This results in potentially two disk seeks for each stored field value you need to retrieve.
It’s worth noting that those Doc IDs are internal to Lucene and have nothing to do with Elasticsearch _id. They are unique only inside each Lucene segment and are incremented with each new document.
DocValues
Lucene stores all the values of a DocValues field consecutively together. This format is also known as columnar/column manner.
Those values can be stored in different formats that optimize their space usage and can be divided into blocks that each can use a different compression format.
Since they are stored in docId order, Lucene just needs to do a sequential read in docId order to retrieve the values of the field for the matched documents.
Into Elasticsearch? Check these out:
How does this all sound? Is there anything you’d like me to expand on? Let me know your thoughts in the comments section below (and hit the clap if this was useful)!
Stay tuned for the next post. Follow so you won’t miss it!
