Luis SenaHow to Optimize FastAPI for ML Model ServingIf you do I/O alongside ML model serving, this will definitely make your FastAPI service faster.6 min read·Sep 14, 2023--13--13
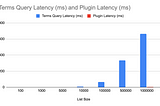
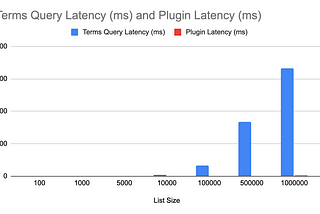
Luis SenaBuilding a Plugin to Improve Elasticsearch Filter Performance Pt. 2Using RoaringBitmaps to include or exclude big lists of integers in Elasticsearch4 min read·Jan 4, 2023----
Luis SenaStop using the _id field in ElasticsearchThese simple changes will dramatically improve Elasticsearch's performance.4 min read·Oct 24, 2022--1--1
Luis SenaBenchmark Elasticsearch sorting and ranking methodsLearn how to rank and sort your Elasticsearch documents efficiently.4 min read·Sep 20, 2022----
Luis SenaImplementing the MessagePack Protocol in JavaSomething that started as a simple dependency removal turned into a 2x performance improvement3 min read·Apr 11, 2022----
Luis SenaSharing big NumPy arrays across python processesWhat is the best way to share huge NumPy arrays between python processes?6 min read·Dec 20, 2021--5--5
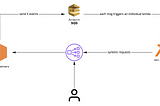
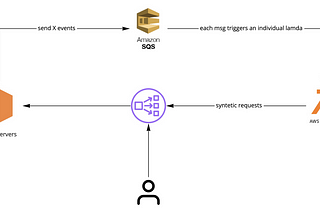
Luis SenaAutomated AWS Load Balancer Warm-UpAutomate AWS load balancer to avoid issues with huge traffic spikes3 min read·Nov 11, 2021--1--1
Luis SenaGunicorn vs Python GILWhat is the Python GIL, how it works, and how it affects gunicorn.7 min read·Sep 29, 2021--1--1
Luis SenainLevel Up CodingBenchmarking Different Methods For Full-Text Search Using ElasticsearchHow to choose between different analyzers and queries to get the best search performance? Benchmarking of course!3 min read·Aug 16, 2021----
Luis SenaAchieving Sub-Millisecond Latencies With Redis by Using Better Serializers.How some simple changes can result in less latency and better memory usage.3 min read·Jul 26, 2021--4--4