Luis SenaHow to Optimize FastAPI for ML Model ServingIf you do I/O alongside ML model serving, this will definitely make your FastAPI service faster.Sep 14, 202313Sep 14, 202313
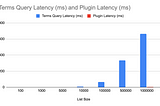
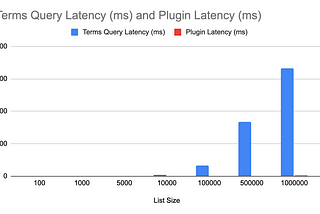
Luis SenaBuilding a Plugin to Improve Elasticsearch Filter Performance Pt. 2Using RoaringBitmaps to include or exclude big lists of integers in ElasticsearchJan 4, 2023Jan 4, 2023
Luis SenaStop using the _id field in ElasticsearchThese simple changes will dramatically improve Elasticsearch's performance.Oct 24, 20221Oct 24, 20221
Luis SenaBenchmark Elasticsearch sorting and ranking methodsLearn how to rank and sort your Elasticsearch documents efficiently.Sep 20, 2022Sep 20, 2022
Luis SenaImplementing the MessagePack Protocol in JavaSomething that started as a simple dependency removal turned into a 2x performance improvementApr 11, 2022Apr 11, 2022
Luis SenaSharing big NumPy arrays across python processesWhat is the best way to share huge NumPy arrays between python processes?Dec 20, 20215Dec 20, 20215
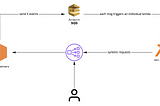
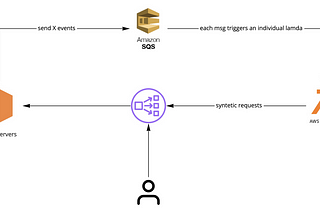
Luis SenaAutomated AWS Load Balancer Warm-UpAutomate AWS load balancer to avoid issues with huge traffic spikesNov 11, 20211Nov 11, 20211
Luis SenaGunicorn vs Python GILWhat is the Python GIL, how it works, and how it affects gunicorn.Sep 29, 20211Sep 29, 20211
Luis SenainLevel Up CodingBenchmarking Different Methods For Full-Text Search Using ElasticsearchHow to choose between different analyzers and queries to get the best search performance? Benchmarking of course!Aug 16, 2021Aug 16, 2021
Luis SenaAchieving Sub-Millisecond Latencies With Redis by Using Better Serializers.How some simple changes can result in less latency and better memory usage.Jul 26, 20214Jul 26, 20214